关于我玩Stable-diffusion-webui的那些事
前段时间AI制图不是很火嘛,说NovelAI的制图效果可以比得上一些画师,然后当时B站就有很多的用AUTOMATIC1111/stable-diffusion-webui加上一堆模型来生成自己的图片
其实我一开始用的是naifu那一套,就是深紫色UI的那一个(图片在下面),而且是跑在colab上面的,这个跟stable-diffusion比的话没有负面Tag这个说法,就是给想要的图片的关键词,然后生成自己想要的图片
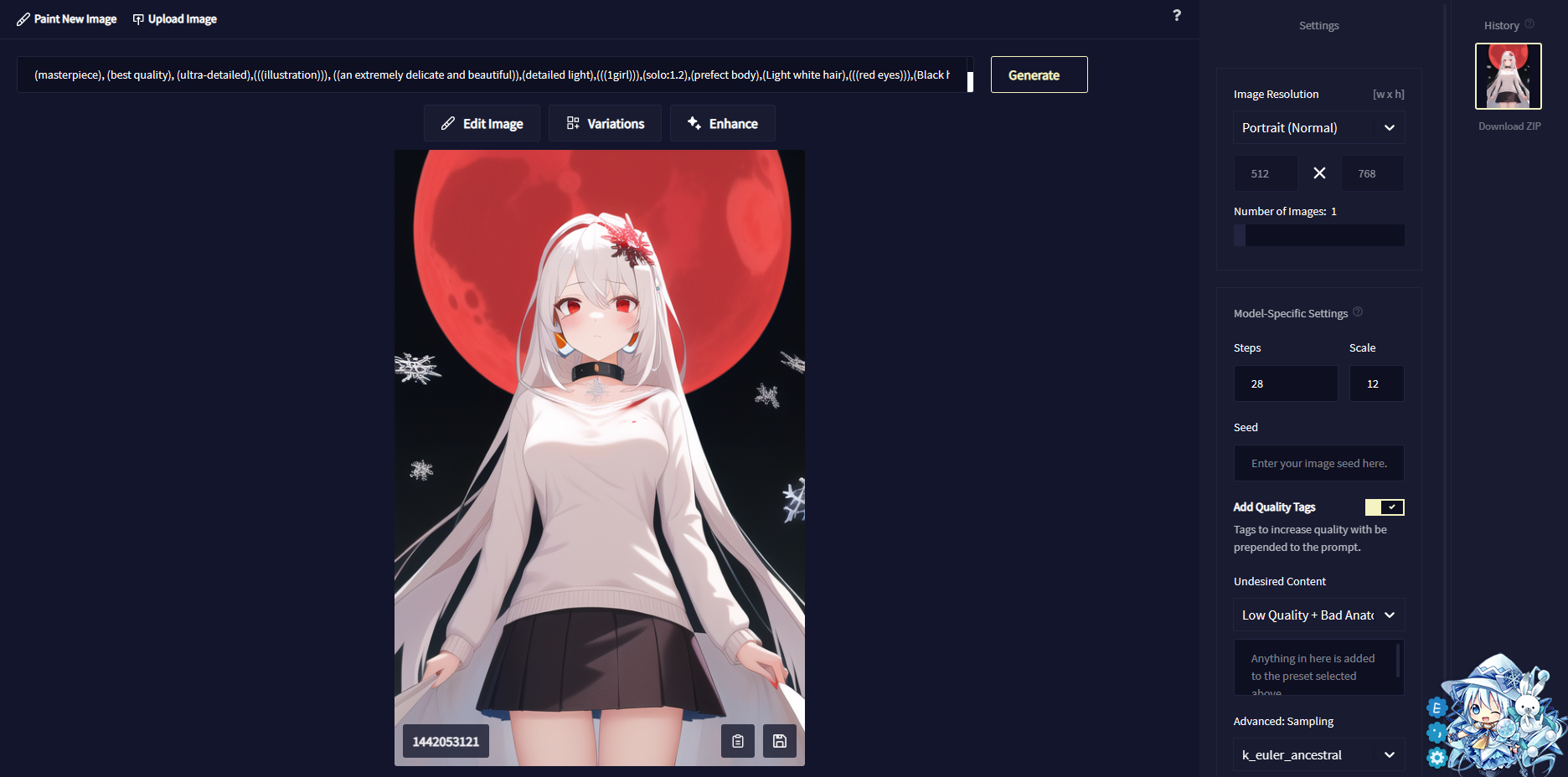
后来看到了Stable-diffusion这一套,换模型啥的会比naifu版更加方便,而且功能也更全面,于是果断转向naifu版
之前是跑在Google Colab上面的,但是最近不知道为什么抽风,stable-diffusion跑不起来(开到一半会自动被KeyboardInterupt),然后我就选择在我电脑上跑了
要是你想在Colab或者Kaggle上面跑的话,我这里也提供下载链接
stable-diffusion-webui 版本:下载链接
naifu-NovelAI 版本:下载链接
安装基本组件
这里我们需要从Github上面把源码给弄下来,打开终端输入
1 | $ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
然后进入stable-diffusion-webui文件夹,里面应该有几个bat或者sh脚本
Windows用户就逮着bat脚本用就行了,而Linux用户就用sh脚本
我们需要关注的是webui-user.bat和webui-user.sh文件,在这两个文件里面我们可以设置我们的各项启动参数,以下以Windows为例
1 | @echo off |
初始状态应该跟我一样是什么也没有的,我的电脑用的是NVIDIA Geforce RTX 3060 Laptop 6G显卡,这个显存虽然看起来很大,但是在机器学习这方面简直是不够用,为了避免爆显存,我们可以在COMMANDLINE_ARGS里面加上一些参数
如果你的电脑用的显卡跟我的差不多,那么只用加上一个--medvram就可以了,但如果你的电脑显卡显存小于等于4G,那么我推荐使用--lowvram作为启动参数
这里附上我的启动参数
1 | @echo off |
这里多的后面会说
设置好启动参数以后,我们还需要下载一个模型,因为没有模型文件是启动不了的(这里模型不一定要是是官方的,官方的模型链接在Dependencies · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com),但你也可以到我的分享站或者社区群体开的站SD - WebUI 资源站去下载)
把你下载好的模型,放到项目文件夹的models/Stable-diffusion文件夹下(没有的话自己创建一个)
我们双击webui-user.bat,它会自动进行环境的安装(当然Python是要预先装好的)
整个过程会比较漫长,如果因为网络原因安装不下来的话试试挂个梯子
当看到如图所示的提示的时候,就说明已经开好了,我们可以访问给出的链接进入webui(默认端口是7860,但我开了一个实例在7860了,所以它就自动顺延到7861,实际使用请注意控制台给出的端口号)
访问给出的链接,我们就能到我们的webui控制台了
安装模型及关键词
这个其实上面提到了,就是把ckpt文件(checkpoint)丢到models/Stable-diffusion文件夹就行
不过我们下载到的东西不一定是ckpt文件,还有.vae.pt和.pt文件,
简单来说,一般遵循以下原则(当然特殊问题特别看待哈,你别提供给你文件的人说放在指定的位置,你还按照我的这个来)
graph TD; .ckpt/.safetensors-->models/Stable-diffusion; .vae.pt-->models/vae; .pt-->models/hypernetworks;
PT的使用方式:Pt放embeddings文件夹,施法输入对应文件名即可
在webui中能直接选择的其实就是models/Stable-diffusion里面的模型,在左上角有个选择框,如果你放进去了选择框里没有的话,你可以点一下左边的刷新
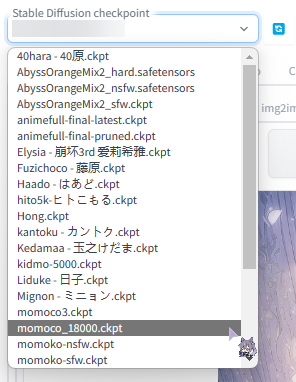
在这里选择我们想要的模型以后,我们就可以开始成图了
开始跑图
刚访问自己的webui,里面应该是像我这个这样
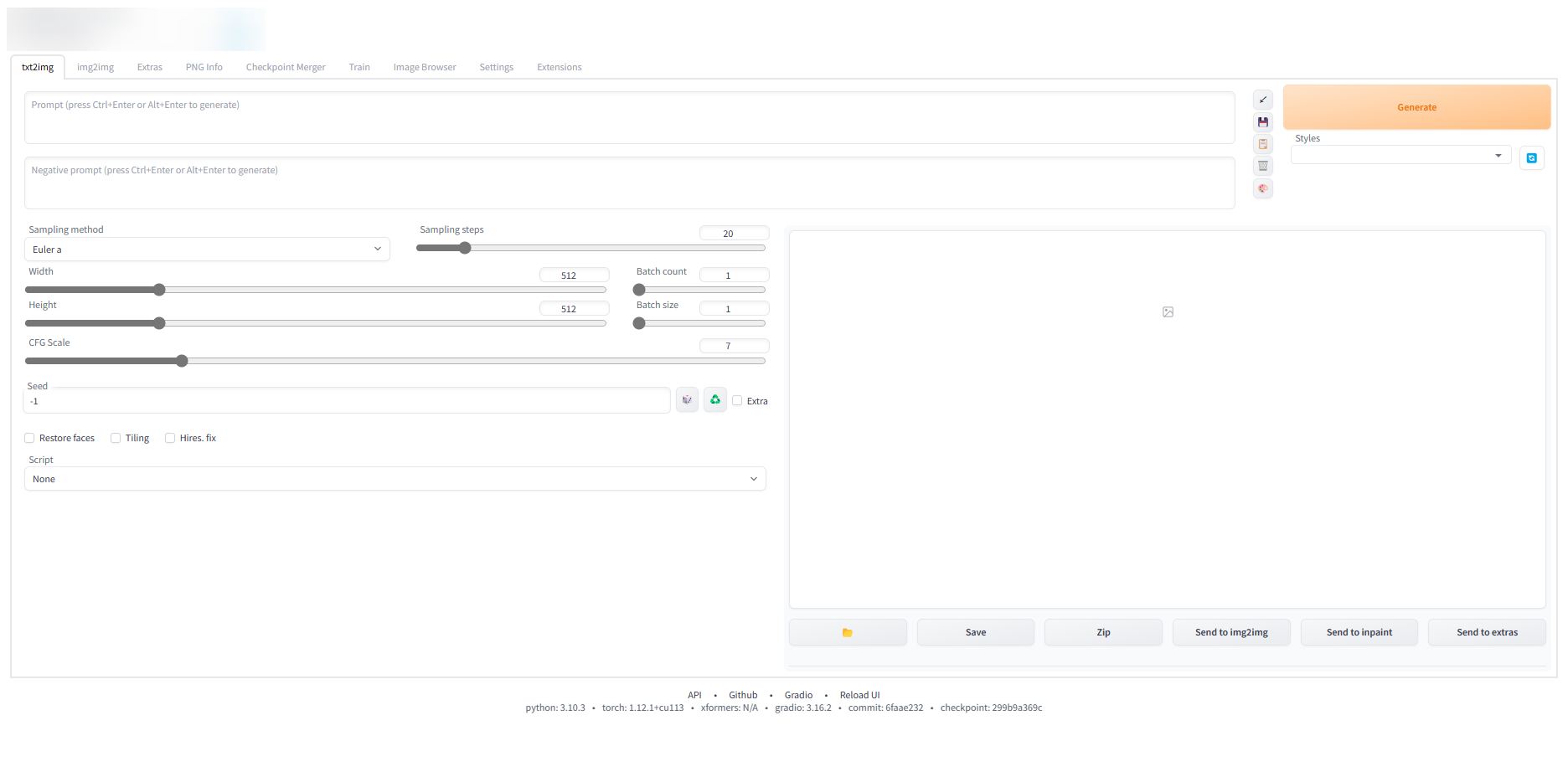
左上角显示目前选择的模型,下面有两个大框框,上面输入的是正面tag(就是你想要的图片里面应该是什么样的),下面的是负面tag(就是避免什么样的图)
然后再往下有个Sampling method是采样方式,就是生成图的时候,要用什么样的方式来对模型进行采样,这里我用得比较多的是Euler a Euler 和 DDIM,右边是Sampling steps采样步数,采样步数越多越接近于你想要的图(不过是类似对数函数那样的,过大反而收益低)
再往下Width和Height就是生成图片的宽度和高度,不宜太大,否则会爆显存(CUDA:Out of Memory),我3060用1280*720没问题
右半边有Batch Count生成图片的数量和Batch size是损失函数,一般只调整数量,关于这两个推荐阅读 → Batch Size的相关问题及如何选择Batch Size的大小 - 知乎 (zhihu.com)
往下有Seed,这个玩MC的应该不用说,种子嘛
还有个选项Hires. fix,这个是高清修复,说白了就是图片放大,同样小心爆显存!!!再往下的可以跳过了
现在,在上面的框框输入以下内容
masterpiece, best quality, official art, extremely detailed CG unity 8k wallpaper
在下面的框框里面输入
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet,
然后点击右边的generate,等待大约两分钟,看到右边生成了一张图片(生成的图片取决于模型以及随机生成的种子,所以每次生成基本都是不一样的)
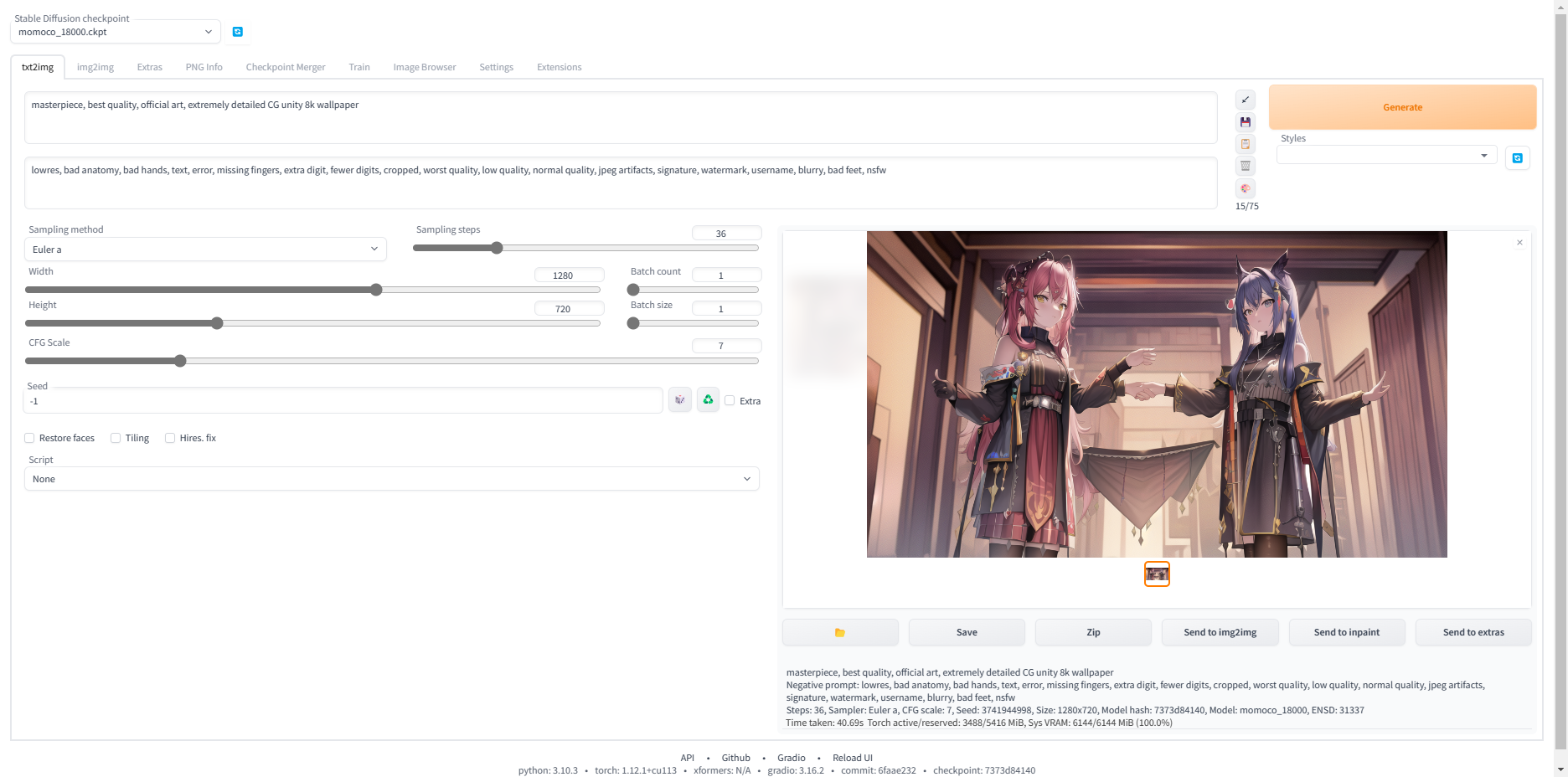
恭喜你!你已经会使用基本的SD功能了!生成的图片可以在outputs/txt2img-images里面找到!
启动项详解
在上面的教程中你会看到,我的启动项多了很多东西。在这里我把上面的东西搬下来
1 | @echo off |
这里PYTHON GIT VENV_DIR这三个不用动(除非你知道你在做啥),我们主要关注下面两个
COMMANDLINE_ARGS是Stable-diffusion-webui的启动项,--deepdanbooru是训练tag的时候用的,可以在图片分割预处理的时候自动推断包含的tag,--medvarm就是怕炸显存才加的,上面也说过了,--no-half-vae主要用于解决生成图片时控制台报modules.devices.NansException的问题(看下面的报错环节)
而PYTORCH_CUDA_ALLOC_CONF是给CUDA用的启动参数,这里garbage_collection_threshold决定了缓存的新旧与否(一般用0.5),而max_split_size_mb是CUDA分割内存的时候的分割快的大小。这个启动参数一般不用设置,除非你要训练模型啥的
插件安装
SD是可以安装插件的,而安装插件的方式很简单,在上方找到Extensions选项卡,然后再选择Avaliable,点击Load from:按钮(就那个橙色的),加载完后下面会出来个列表,在里面选择自己想要的就可以了
我这里装了一个image browser用于看图
报错以及相关的解决方式
生成图片时控制台报modules.devices.NansException

在启动参数里面加入--no-half-vae即可
加载模型时出现RuntimeError
1 | changing setting sd_model_checkpoint to animefull-final-pruned.ckpt: RuntimeError |
解决方式:换个模型,该模型可能已经损坏
加载模型时出现AttributeError
1 | -----> !!!! The file is most likely corrupted !!!! <----- |
(治标不治本)在启动项添加--disable-safe-unpickle
资源推荐
模型下载站
主页 | SD - WebUI 资源站 (123114514.xyz)
首页 - NovelAI - Share4Nothing (share4nothing.cf)
AI绘画模型博物馆: http://aimodel.subrecovery.top
Tag列表
上述资源的QQ频道
NovelAI中文频道(u31uiz208r)
魔导师学院(2p6k6vzg5i)
没有频道功能点这个激活频道功能:点击链接加入QQ频道【接驳巴士】:https://pd.qq.com/s/47hvnz3w2
模型训练
云平台
Kaggle: Your Home for Data Science
欢迎使用 Colaboratory - Colaboratory (google.com)(要梯子)
梯子
用户注册 | 三分机场 (xn–ehq00hgtfdmt.xyz)
Airports 个人机场/订阅汇总 - Airports (share4nothing.cf)
P站资源
本人:喵呜初音 - pixiv
 微信
微信- 支付宝