
最近在家里虽然有上课(学校开学了),但是中午两个半小时的休息时间以及晚上的自由时间是真的闲,在想要干什么……然后我在我的学弟的电脑桌面上发现了八爪鱼,想起了他用八爪鱼抓一言库的时候,我就在想:为什么我不自己做一个抓一言的爬虫呢?说干就干,于是我就开始坐了起来……
下面,是我的个人开发日记,包含回忆,有些细节可能记得不是很清楚
项目地址:https://github.com/GamerNoTitle/Hitokoto-Spider
2020年2月10日 星期一 天气:不很好
今天是学校开学第一天,钉钉的会议功能真的菜,视频延迟3秒钟,互动板延迟3分钟……而且这个会议可以回看不能下载???拿fiddler抓包去……
(12:00)开始做爬虫了,先到一言去看看API是怎么用的先。在官网,可以看到下面这个表格(为了方便,我直接把源码拿过来了)
| 时间 | 影响Api | 调整 |
|---|---|---|
| 2018年6月之前 | 旧版API(http://api.hitokoto.cn和https://sslapi.hitokoto.cn) | 旧版API将在6月份之前以切换解析的方式合并到v1API中。也就意味着调整之后请求此API无异于请求v1API。调整后此接口的稳定性将不再受到维护。 |
| 2018年7月之前 | v1API(https://v1.hitokoto.cn) | v1API将发布最终版本。v1接口将会在未来存在较长时间(即使v2发布,请放心使用)。 |
| v2 发布(时间未知) | v2API(域名未知) | 上线v2API。 |
这个是一言的几个api的地址,我选择的就是用的https://v1.hitokoto.cn
拿到了api,我要看看访问出来的效果是怎么样的,于是我又访问了这个地址,获得了一大串文本
{
"id": 79, //一言的ID
"hitokoto": "所以,他们的祭典还没结束。", //一言内容
"type": "a", //类型,具体可在官网查阅,这里a是Anime即动漫
"from": "我的青春恋爱物语果然有问题", //一言出处
"from_who": null, //谁说的话
"creator": "阿布碳。", //提交此条目的用户
"creator_uid": 0, //用户的uid,可以不看
"reviewer": 0,
"uuid": "f6aa4116-5a0f-4ab0-807a-bf3838a5fd23", //用户的uuid,可以不看
"created_at": "1468605909" //何时创建,这里是以时间戳的方式展示
}我看着:这玩意怎么格式这么像json呢???

直到我往下拉,发现:
这塔喵不就是json嘛……(上面的注释是我加入的)

搞清楚了返回出来的结果的组成后,我们就可以开始撸代码了!
打开VSCode,新建一个文件夹,在这个文件夹里面进行修改
首先确定我需要用什么来模拟http请求,因为我自己用过@Dawnnnnnn/bilibili-live-tools这个项目,而且在用这个项目的时候,特别是在学校的服务器上面挂,那个Windows Server 2016 DataCenter装个requests运行库都难,所以我特别记得requests这个库可以模拟http请求,先装上再说!
于是我在powershell内打了
$ pip install requests来安装我的requests运行库,接着,在我的python文件内打入
import requests as r因为本人比较懒,所以喜欢把运行库简写,加入了as r我就可以不用打那么多字母了,真的方便
接着,要先搞清楚requests库的用法,于是乎我又去查了一下,查到这几个函数
requests.get(‘https://github.com/timeline.json’) # GET请求
requests.post(“http://httpbin.org/post”) # POST请求
requests.put(“http://httpbin.org/put”) # PUT请求
requests.delete(“http://httpbin.org/delete”) # DELETE请求
requests.head(“http://httpbin.org/get”) # HEAD请求
requests.options(“http://httpbin.org/get” ) # OPTIONS请求那么我要获得结果,采用了GET请求,然后在我的项目中打入了
res = r.get('https://international.v1.hitokoto.cn/')这样就可以把获得的结果赋给res,然后通过调用res的值来获得我们想要的结果,接着运行一次我们的文件
import requests as r
res = r.get('https://v1.hitokoto.cn/')
print(res)然后返回的值为:<Response [200]>
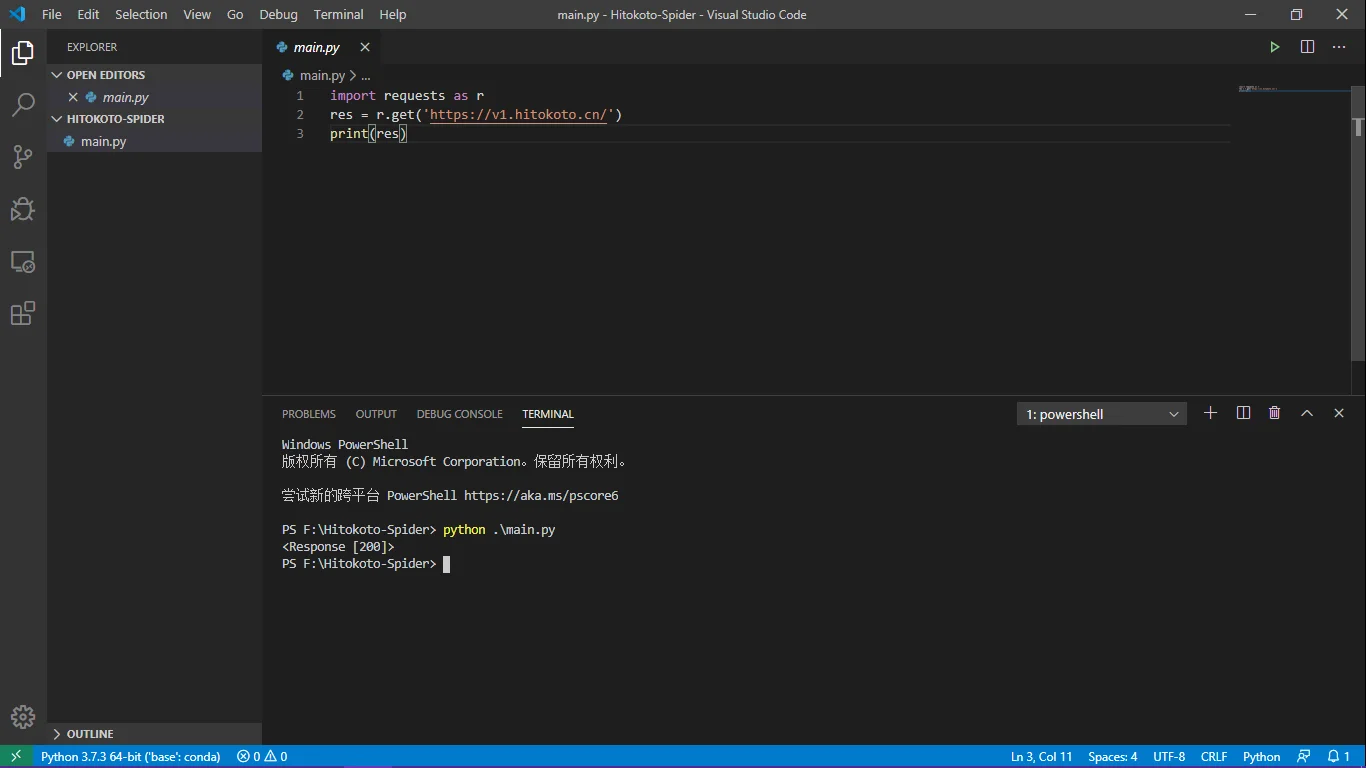 这不是状态码嘛???我不要这玩意儿啊,我要结果。。。
这不是状态码嘛???我不要这玩意儿啊,我要结果。。。
然后我就commit了一下,盖上我的垃圾Lenovo,然后去睡觉了……
2020年2月11日 星期二 天气:还是不很好
今天继续开发,昨天拿到的结果是个状态码,然后我又有思路了!
我就在print中动一下手脚,给被打印的res加上一个参数,然后代码就变成了
import requests as r
res = r.get('https://v1.hitokoto.cn/')
print(res.text)接着就给我输出了我想要的东西嘿嘿
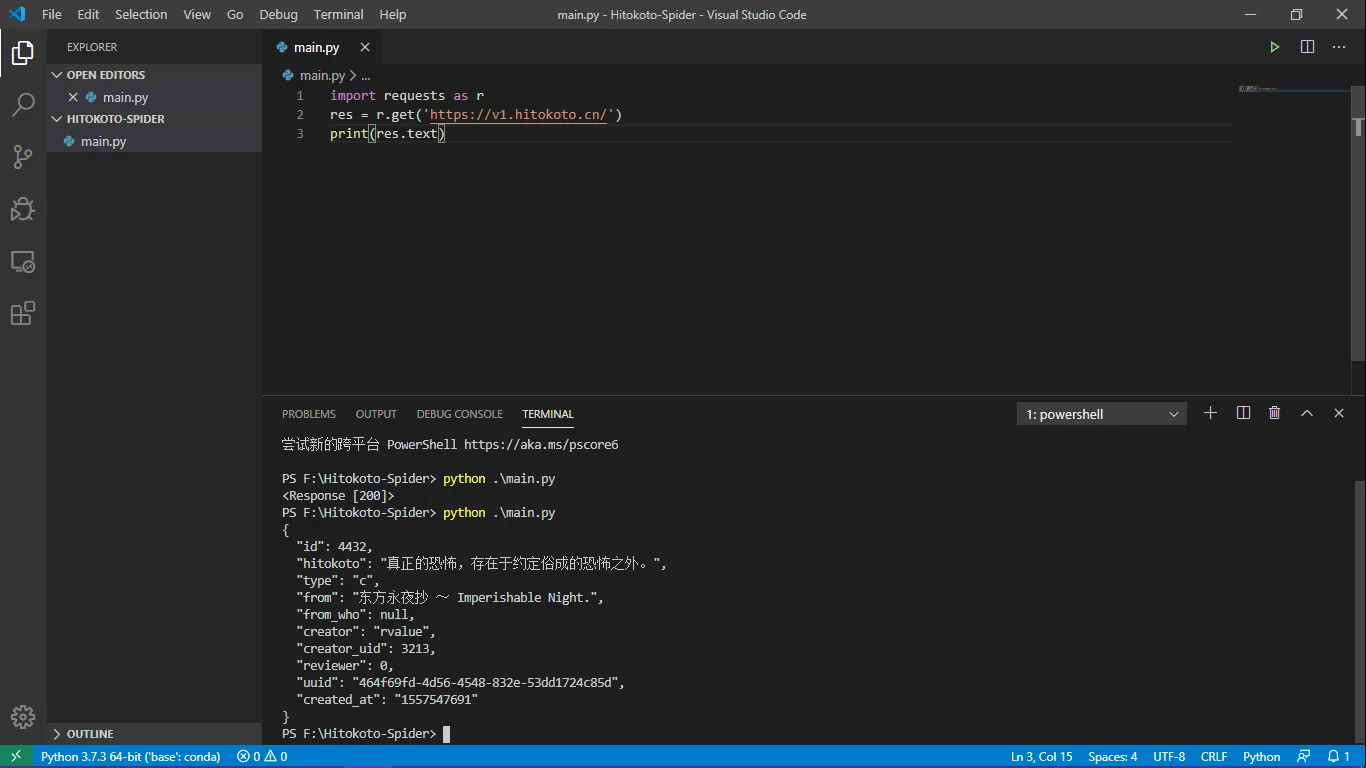
这个项目本来想跟学弟@Soulxyz一起做的,然后我就先把这个雏形push到了仓库里面,他也fork了,然后回来给我的是一个叫做csvdomo.py(点击可下载)的文件(我寻思你是不是想打csvdemo???)
我打开了,然后发现:你这不是并发获取10次都是一个结果吗???你这不重新获取不是每次都一样的吗???
于是我决定放弃他这里,我自己来弄这个项目……后来他告诉我,用一言的国际节点可以有更高的QPS,然后我就转用国际节点了……
接着下一步是要重复抓取,对于这一部分,我想到的是让用户输入要抓取的次数,类型为int,命名为num,然后采用for循环重复抓取,就写了下面的这一段
print("请输入抓取的数量,如果要抓取全部请到https://hitokoto.cn/status查看现在的一言总数并填入:")
num=input()
for i in range(num):
res = r.get('https://v1.hitokoto.cn/')这样子来实现重复抓取的功能,至于为什么如果要抓取全部还要输入,因为那个数字我是真的拿不到啊……
终于实现了抓取的功能,接下来要实现写入文件的功能
我的想法是写入csv文件,因为我自己在华南理工学习的时候就用过相关的函数,所以我就去搜索了一下,结果发现python原生支持csv,不需要用到pandas,所以我就调用了自带的csv库
(要上课了,先撤了)
(16:30)我回来了!现在就是要搞定写入csv库的问题,我在网上找到了相关的方法:
先打开一个文件,然后把这个文件设定为file变量,然后def两个函数,一个创建,一个写入,就像下面这个亚子:
import csv
def create_csv(path):
with open(path,"w+",newline="",encoding="utf8") as file:
# 打开文件,也相当于一个回车,避免覆盖文档
csv_file = csv.writer(file)
head = ["id","sort","hitokoto"] # 创建csv表头
csv_file.writerow(head)
def append_csv(path):
with open(path,"a+",newline='',encoding="utf8") as file:
csv_file = csv.writer(file)
data = [inputs]
csv_file.writerows(data)这样我就定义了两个函数,然后在下面直接用这个函数就好了
再加上上面写过让用户填入输出路径和爬取次数的相关代码,直接把变量拿过来用就好了
print("请输入文件输出名(请自行输入后缀,文件以csv的方式保存):")
path=input() # 输出文件
print("请输入抓取的数量,如果要抓取全部请到https://hitokoto.cn/status查看现在的一言总数并填入:")
num=int(input()) # 抓取数量将path用于文件的路径,将num用于下面的抓取次数,完美!
然后在下面,将抓取到的数据排版一下
data=res.json()
if data["type"]== "a": sorts=("Anime") # 自动把分类码还原为分类
if data["type"]== "b": sorts=("Comic")
if data["type"]== "c": sorts=("Game")
if data["type"]== "d": sorts=("Novel")
if data["type"]== "e": sorts=("Myself")
if data["type"]== "f": sorts=("Internet")
if data["type"]== "g": sorts=("Other")
inputs=[data["id"],sorts,data["hitokoto"]]
# print(res.text) # 输出一言,如需要把最前面的#去掉即可
append_csv(path)这样就完成了写入操作!写入csv的操作搞定了以后,最后剩下除掉重复的结果,不然会有很多同样的话,这是最麻烦的部分……
开始我的想法是:每次获取到一个结果以后,将id存入存入一个存储变量叫做ids,开始先初始化
ids=[]这样将ids初始化为一个空列表,然后往这个空列表里面加入id,每次遍历一次ids里面的id是否与获取到的id相同,如果相同则说明获取到了重复的话,将这个结果舍弃,然后重新获取
将我的重复剔除的功能写出来,就像这样(从之前的commit弄出来的)
ids=['0']
i=1
for i in range(num):
res = r.get('https://international.v1.hitokoto.cn/',timeout=60) # 得到服务器回应,此时回应的内容为json文件(res.text)和状态码
data=res.json() # 将获取到的结果转为json字符串
t=1
for t in range(i):
if data["id"]==ids[t]:
# ID已经存在,即已经抓到过,这地方可能会报BUG,目前没修(数组越限BUG)
break
else:
t=t+1 # 自增
if t==i:
ids.append(data["id"])
if data["type"]== "a": sorts=("Anime") # 自动把分类码还原为分类
if data["type"]== "b": sorts=("Comic")
if data["type"]== "c": sorts=("Game")
if data["type"]== "d": sorts=("Novel")
if data["type"]== "e": sorts=("Myself")
if data["type"]== "f": sorts=("Internet")
if data["type"]== "g": sorts=("Other")
temp=[data["id"],sorts,data["hitokoto"]]
print(res.text)
append_csv(path)接着就会发现,运行着运行着,告诉我数组越限了?!!!

这个问题就真的很烦,因为C++是允许数组越限的,但是python不允许,会直接冷不丁给你报错,所以每次遇到这个问题我都不是很想去理它,但是不理它我的程序就运行不下去了啊!!!所以我先把检测重复这一段注释掉了,合上垃圾Lenovo,睡觉!
2020年2月12日 星期三 天气:下雨了啊!
今天早上上课上到11点20分,开始写代码,用一中午想把这个重复检测的功能写完……

想到昨天的数组越限就头疼,我打算放弃这个方法,不存列表了!
我记得当时在华工有用过像array[t]这样的东西,于是我想起了一个利器——array数组!
新的思路是这样的:将得到的数据存入数组名为temp,开始先初始化这个变量:
from array import array
temp = array['i',[0]]至于我为什么在里面写一个0,是因为我发现我不这么做的话他会给我报错……
这样就初始化了一个名为temp类型为int的数组,里面含有一个元素0。然后在下面每次获取完id以后就将其存入temp变量
temp.append(data["id"])通过这样,每次再遍历temp里面的东西,只要重复,就说明抓过,没重复就说明没抓过,就可以达到去掉重复的效果!
for i in range(num):
time.sleep(delay)
print("正在获取新的一言……")
res = r.get('https://international.v1.hitokoto.cn/',timeout=60)
# 得到服务器回应,此时回应的内容为json文件(res.text)和状态码
data=res.json() # 将获取到的结果转为json字符串
temp_minus=temp.count-1
if temp_minus!=0:
t=1
print("正在检测是否抓取过结果……")
for t in range(temp.count):
if(int(data["id"])==temp[t]):
print("发现已经抓取到的结果,正在丢弃……")
i=i-1
break
elif(t==temp.count-1):
print("未抓取过的结果,正在存入文件……")
if data["type"]== "a": sorts=("Anime") # 自动把分类码还原为分类
if data["type"]== "b": sorts=("Comic")
if data["type"]== "c": sorts=("Game")
if data["type"]== "d": sorts=("Novel")
if data["type"]== "e": sorts=("Myself")
if data["type"]== "f": sorts=("Internet")
if data["type"]== "g": sorts=("Other")
inputs=[data["id"],sorts,data["hitokoto"]]
# print(res.text) # 输出一言,如需要把最前面的#去掉即可
append_csv(path)
temp.append(data["id"])
end_Pro=datetime.datetime.now()
print("已完成数量:"+str(i+1)+',已经用时:'+str(end_Pro-start_Pro))
break
else:
if data["type"]== "a": sorts=("Anime") # 自动把分类码还原为分类
if data["type"]== "b": sorts=("Comic")
if data["type"]== "c": sorts=("Game")
if data["type"]== "d": sorts=("Novel")
if data["type"]== "e": sorts=("Myself")
if data["type"]== "f": sorts=("Internet")
if data["type"]== "g": sorts=("Other")
inputs=[data["id"],sorts,data["hitokoto"]]
# print(res.text) # 输出一言,如需要把最前面的#去掉即可
append_csv(path)
temp.append(data["id"])
end_Pro=datetime.datetime.now()
print("已完成数量:"+str(i+1)+',已经用时:'+str(end_Pro-start_Pro))最后写出来的效果是这样子的,然后问题又出来了,我的temp.count似乎不能被它正确识别出来,于是我打开了一个新的文档,测试一下这个玩意输出长什么样子:
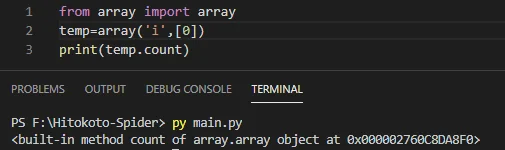
emmmm,这是啥???

然后我又去求助万能的百度,网友们告诉我可以用len(temp)来获得数组的元素个数,然后我就把这玩意改了,终于可以运行了!!!接着问题又来了。。。
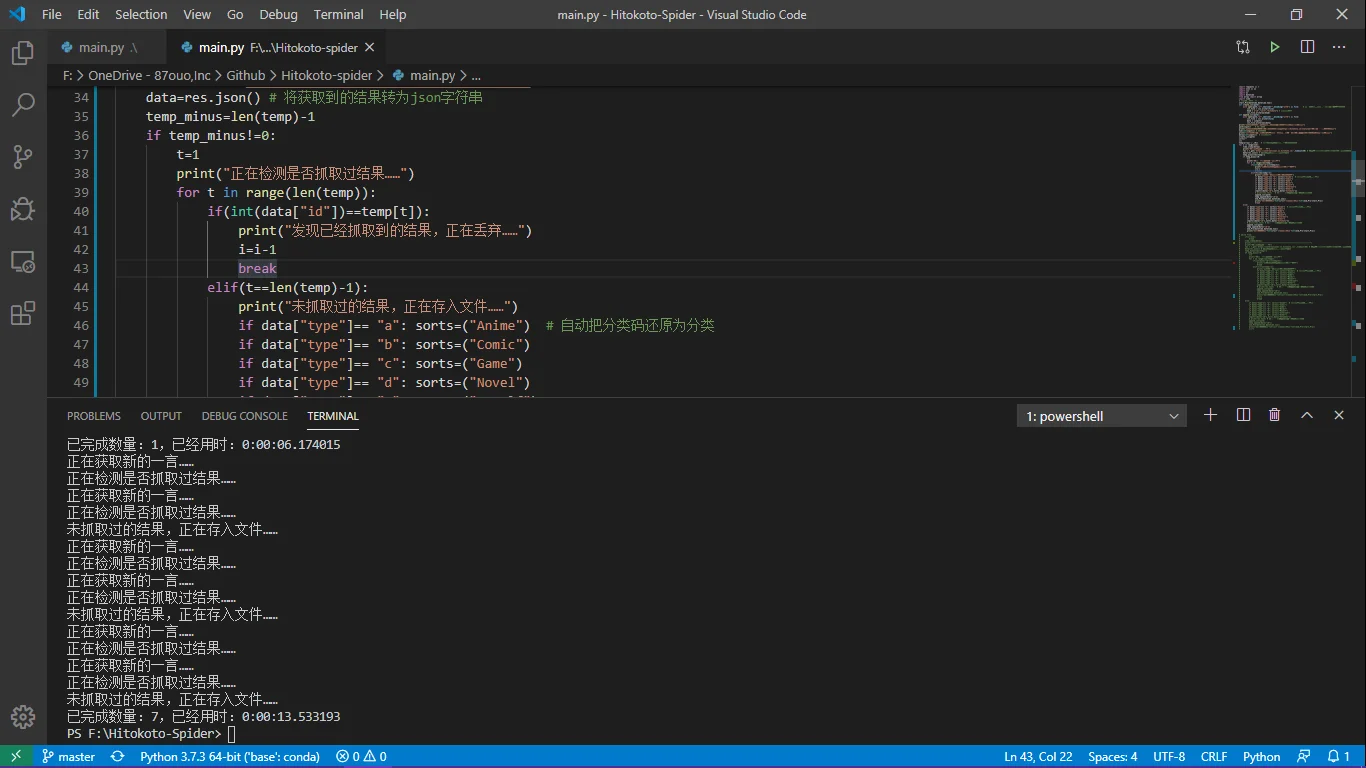
这是???这怎么不连续啊,这数字???我想到可能是抓到重复的时候算抓了,就导致了i+1(不过这次测试挺非的,这么多次一样。。。非到极致也是一种欧!)
后来我试试加一个i=i-1在相应位置,结果还是不行,我就想到可能是局部变量改不动???
我就自己定义一个变量,用while循环呗……然后我就改用while循环
这下终于可以了,抓到的结果没有抓到重复的(因为中途连接超时导致程序停止运行了,所以只抓了2159条,本来是想把整个一言库抓完的,点我下载2159条数据,请用UTF8解码后保存为gbk才能在Excel上查看哦)
终于搞定啦!!!这个项目终于能够按照期望运行了!
接下来要解决的问题:
- json配置文件支持
- GUI支持
题外话:
这是我第一次做爬虫,把学到的python技术用出来。项目已经上传到https://github.com/GamerNoTitle/Hitokoto-Spider
有人愿意与我一起做项目我也非常开心,希望大家能够活用此项目,不要再用什么八爪鱼抓一言了,那种要VIP的软件对我们这种程序员来说一点也不友好,还不如自己来……
2020年2月16日 星期日 天气:还是下雨天……
今天晚上,我对爬虫进行了优化,之前我上面就说过要提供json配置文件的支持,今天的目标就是这个!走起!
首先,要新建一个json文件,里面包含的参数如下:
{
"path": "Hitokoto.csv", //文件输出路径
"times": 3, // 抓取次数
"delay": 0, // 抓取延迟,针对一言的QPS设置
"timeout": 60, // 连接超时时间(单位:秒)
"from": false, // 来自什么作品
"from_who": false, // 来自谁
"creator": false, // 哪位用户提交的
"created_at": false // 何时提交
}其中,文件输出路径是str变量,抓取次数、抓取延迟、抓取超时都是int变量,from、from_who、creator、created_at都是bool型变量,这就表示它只支持true和false
搞定config文件的内容后,反过来对代码进行添加,定义一个读取json文件的函数,命名为read_config()
def read_config():
with open("config.json") as json_file:
config = js.load(json_file)
return config这样,我使用conf = read_config()就可以获得文件中的所有内容,文件读出来的结果应该是这样的(如图)

把程序再美化一下,运行后发现,出了BUG
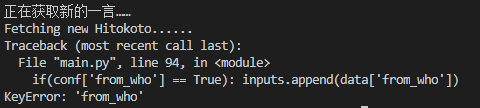
KeyError???WTF???你不是能正常读入的呢嘛?这又是个什么鬼错误……
上网搜索说是读不到相关的东西,不在字典中,我就想在上面提前置顶from_who的值,但是一言返回的结果里面的东西我也修改不了啊……所以还是要解决KeyError的问题
上网一搜,全部都是用dict导致的问题。我寻思:我怎么也没有操作字典吧。。。
算了,先上传吧,明天再修复from_who的BUG……
我的友人表示想建立一个一言的镜像站,所以要求我把其他的参数给加上,我先加吧……
尴尬……又出现了KeyError的问题,这次是creator_uid和reviewer,算了明天弄吧……睡觉!
2020年2月17日 星期一 天气:晴天
今天早上起来,换了台电脑,还是有keyerror的错误,然后去问了一下大学导师,他告诉我是data里面没有这个key的项的问题,然后我又倒回去看发现,上面提到的三个数值有些结果是没有使用双引号括起来的,基本都写的null或者是0,这样就导致data里面没有这个key,进而导致keyerror
所以我是打算用try和except这两个东西进行解决。
在代码里稍作修改,加入try和except
if(conf["from_who"] == True):
try: inputs.append(data["from_who"])
except KeyError: inputs.append("null")在会报KeyError错误的地方都进行这样的修改,然后进行调试
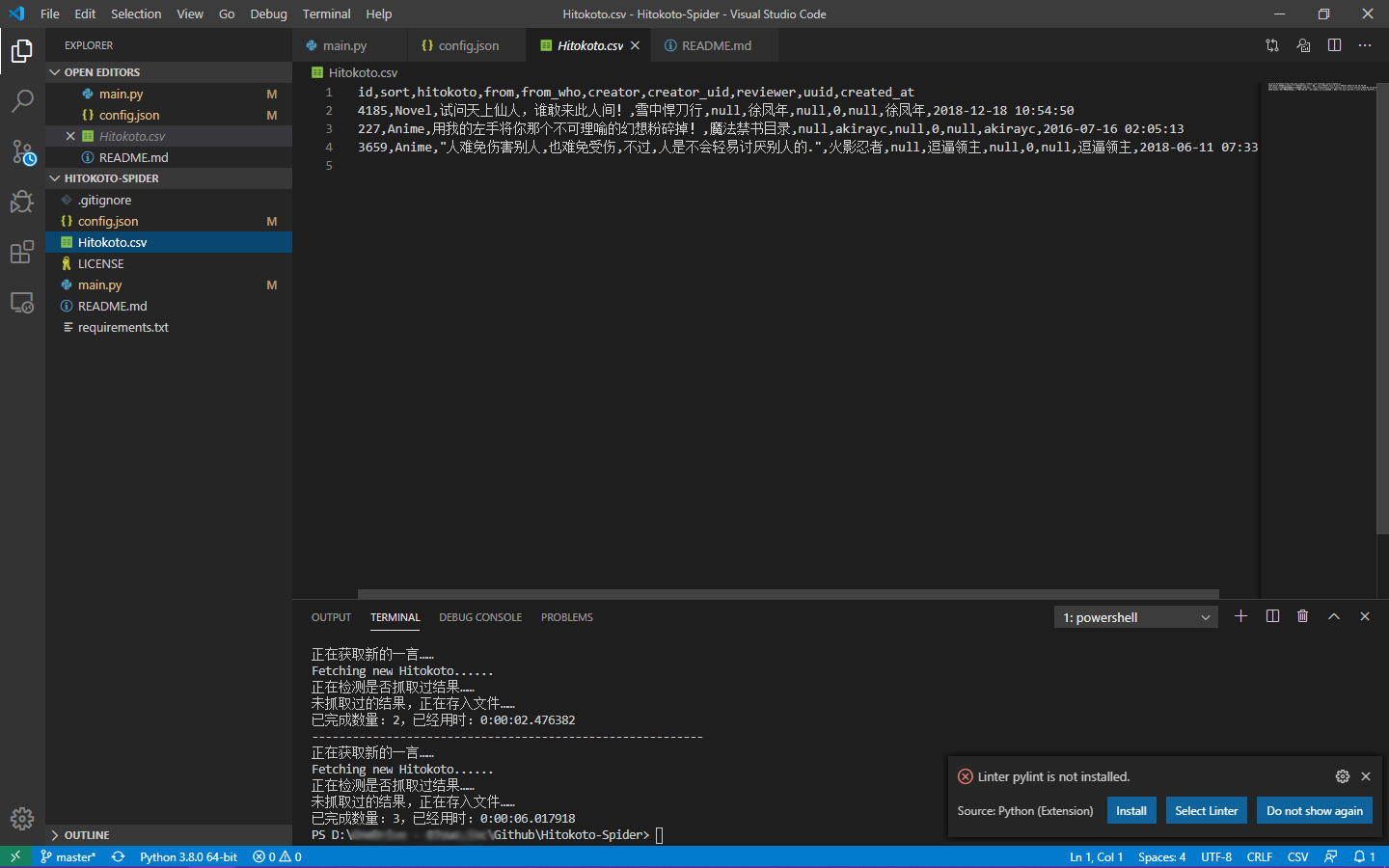
终于可以啦!!!推送代码,项目完成!
接下来就是要加入GUI支持了,但是我其实不是很会做GUI,所以说别抱太大希望,很有可能鸽掉……
