用Python和Flask打造属于自己的API
先上api链接:https://api.ninym.top
文档链接:https://ninym.top
快速开始
环境安装
首先既然是用python+flask,这两个东西肯定要装好的嘛~ Python的安装我就不讲了,主要说下flask
很简单,安装命令就一行
Linux
1 | pip3 install flask |
Windows
1 | pip install flask |
因为我这里已经安装过了,所以写的是Requirement already satisfied,如果没有安装过的话会进入安装状态
# Hello World
既然要用flask框架,那就首先要引用,在python中,我们可以使用import语句来引用外部模块
1 | from flask import Flask |
当然可以在后面加上as xxx给它取个别名(特别是对于那些名字很长的modules,下面会讲)
接下来我们创建我们的第一个flask程序
1 | from flask import Flask |
然后我们直接运行命令python <file>.py就可以运行我们的服务器了(Linux请使用python3 <file>.py,下面不再赘述,只讲Windows,Linux用户请自行替换)
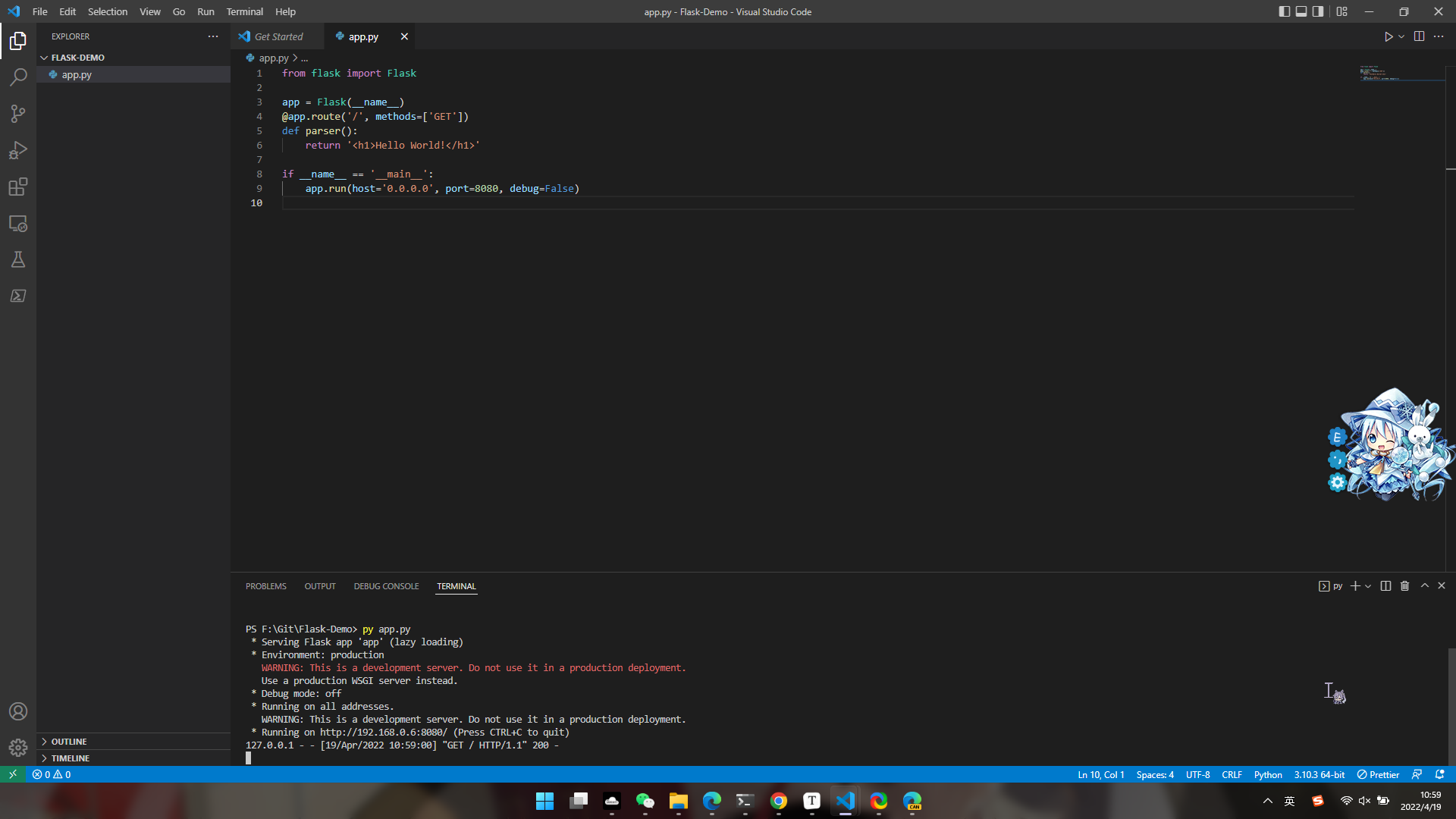
然后我们在浏览器访问我们的网站,在这里可以使用127.0.0.1:8080访问,因为服务器就是部署在本机器上面的,打开后就会显示Hello World了
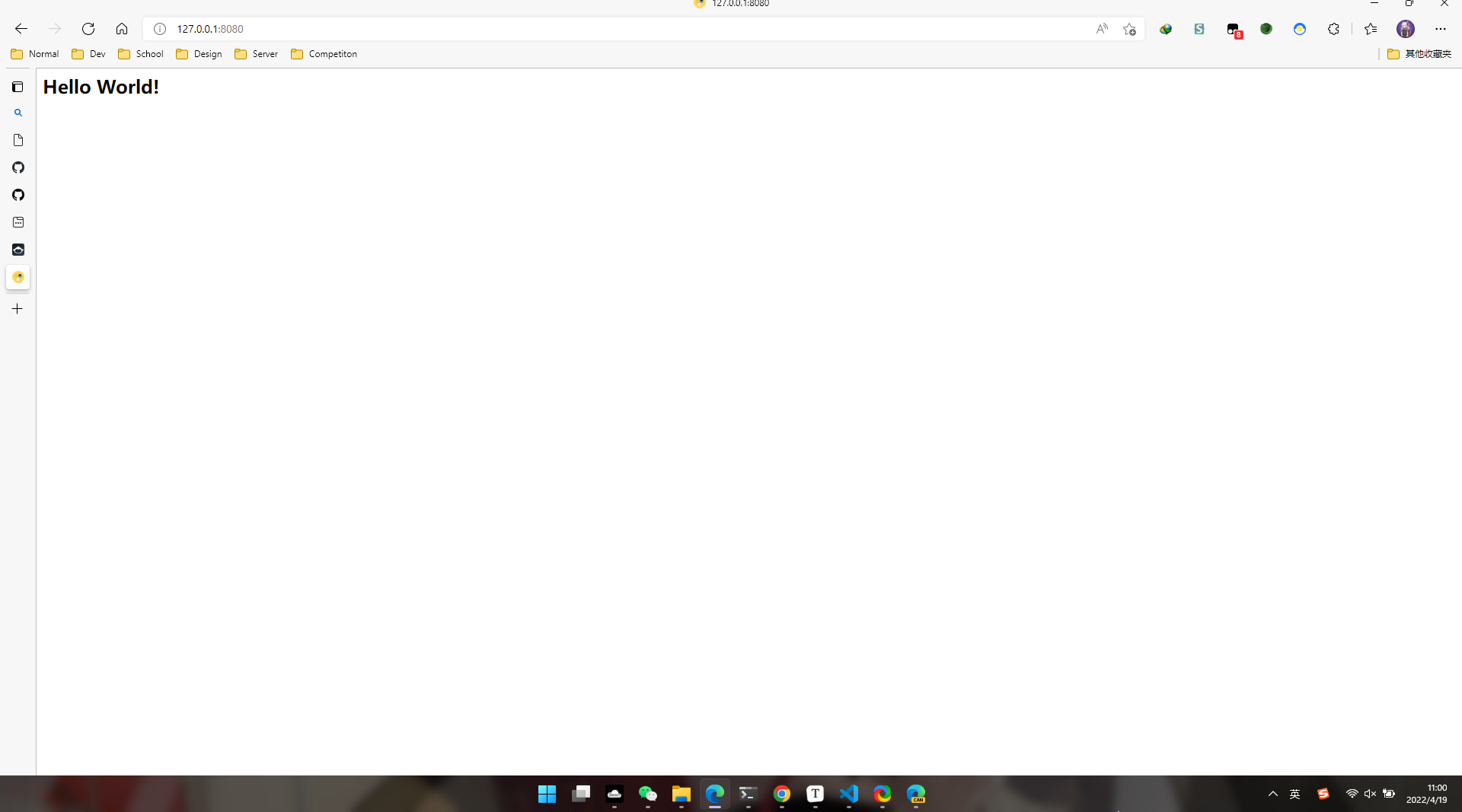
注:图标是我的浏览器本地缓存,正常情况下网站是没有图标的(因为没有设置)
太棒啦,你现在已经学会创建Flask程序啦!
我的Flask程序
网易云音乐下载
我在玩这个东西的过程中,主要是想把我的网易云音乐的API给重制一下(之前是用JavaScript写的烂代码,而且不会自动重命名,就想把这个功能完善一下),所以在我住院的期间,我就开始干起了这个东西。
首先先新建一个utils文件夹,里面放各种自制模块,然后新建了NeteaseCloudMusic.py来写我的这部分的代码
1 | import requests as r |
首先因为涉及到网络,所以就引入了一个requests模块(精简版的utllib),然后把我原来在JavaScript写的逻辑搬过来,就形成了NeteaseDownload这个函数,那就剩下重命名没搞定。因为手动解析网易云音乐的网页很麻烦,所以就用了一个叫做beautifulsoup4的模块来帮助我解析。在这里直接搜索<em>元素,限定class为f-ff2,这样就可以找到歌曲名;在用re寻找<a>标签下class为<s-fc7>的内容,这些元素和class都是通过分析网易云音乐网站的源代码获得的。当然当用户输入了非法的id的时候,在网易云上就无法获取到歌曲信息,这时候通过搜索作者中内容为${escape(x.beRepliedUser.nickname)}的情况就可以判断,向用户返回非法id的信息
接着在主程序中注册网易云音乐的解析器,给网易云音乐的API设定路径即可
1 | from utils.NeteaseCloudMusic import NeteaseDownload |
Github RELEASE下载次数饼状图
这个用到了matplotlib.pyplot这个模块,上面说这种模块名字很长的就可以给它命个别名,所以在引入的时候就给它改了个名字
1 | import matplotlib.pyplot as plt |
然后就是疯狂地写代码,Github的下载次数是有API可以获取的(不过有QPS就是了)
从Github获取次数后进行json解析,把RELEASE版本信息和次数提取出来,接着放到图片里就可以了,总之就是写成了下面这样
1 | import requests as r |
然后还是一样在主程序中注册路径即可
1 | from utils.Github import ghParser |
部署服务
部署服务我选择的是Railway这个平台,相比于heroku来说比较快,而且不用绑卡就能绑定域名,很方便
在这上面新建环境,选择Deploy from Github Repo,然后选中自己的仓库就行了
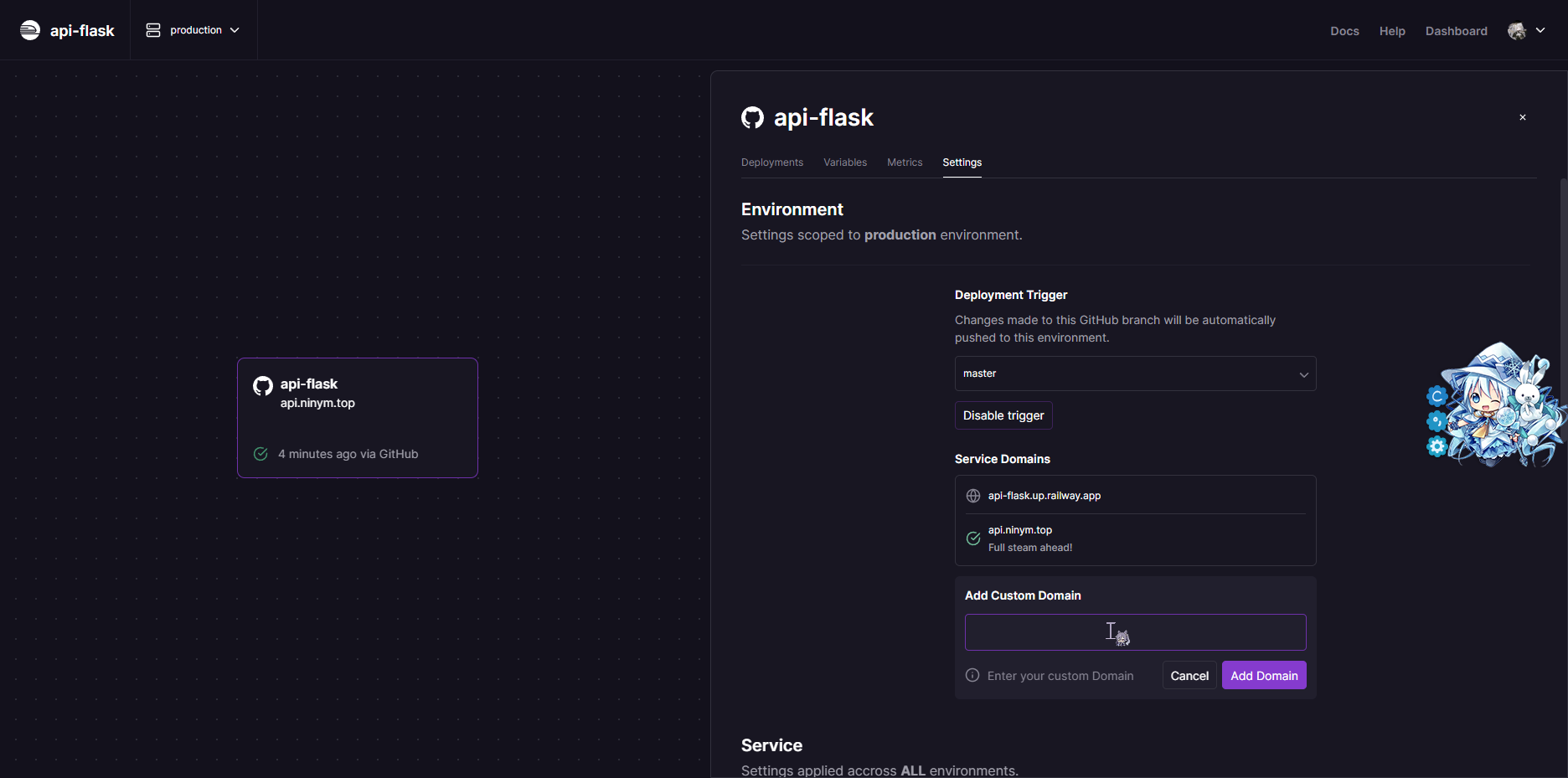
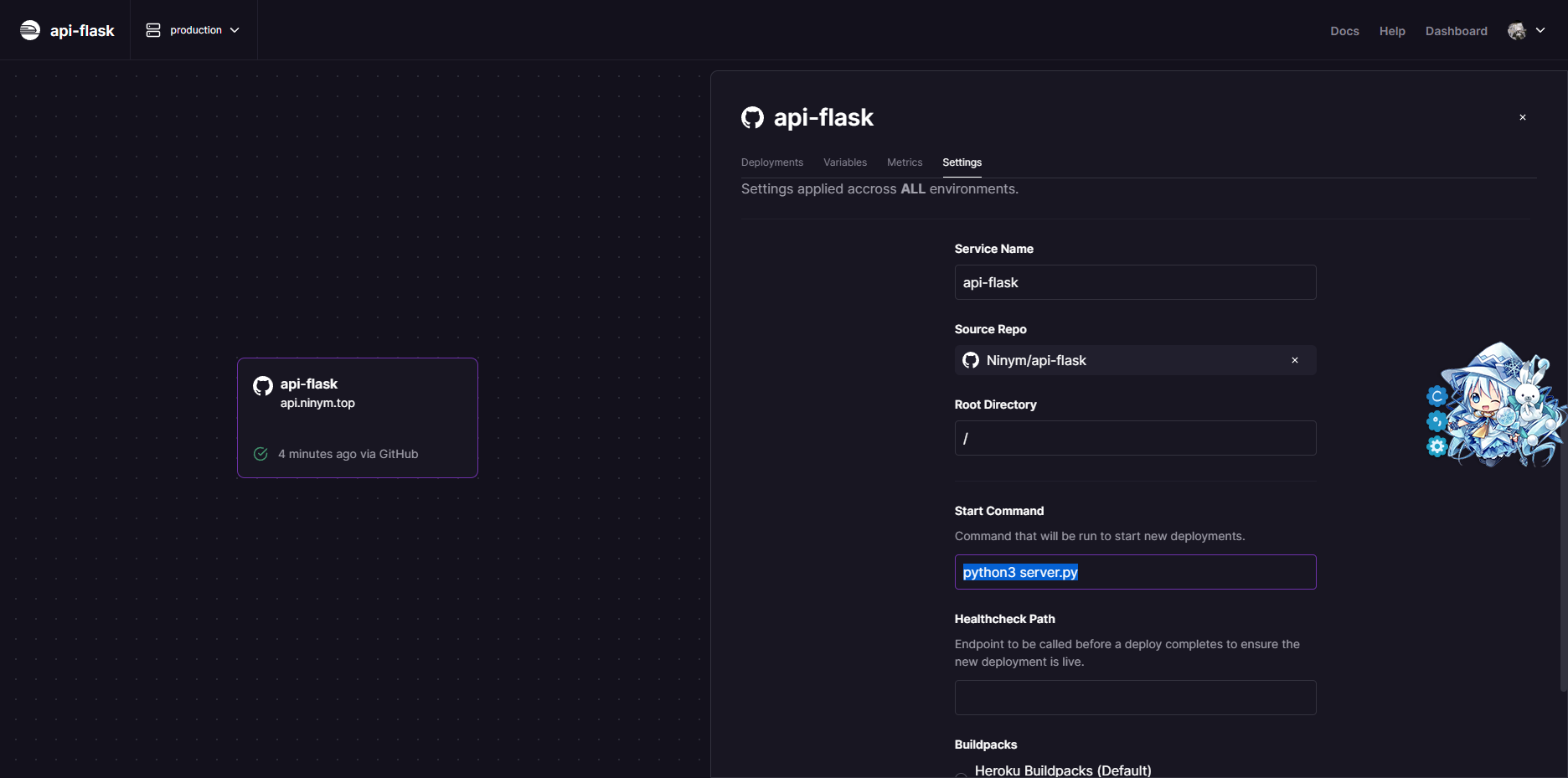
然后在项目的设置中进行自定义域名的绑定和启动命令的修改即可
结语
总的来说,用Flask还是比较方便的,何况我还是比较会用Python,能够做出很多奇奇怪怪的东西,但是就是缺少点子
如果你有什么想法也可以在评论区留言,我说不定会做出来呢?
 微信
微信- 支付宝